Deep Learning
El Deep Learning, o aprendizaje profundo, es una subcategoría del Machine Learning. Se basa en la utilización de redes neuronales artificiales con múltiples capas para aprender y extraer características de los datos.
El Deep Learning se utiliza en diversas aplicaciones, como la visión artificial, el procesamiento del lenguaje natural (NLP), la traducción automática, la detección de fraude, la identificación de objetos, entre otras. Debido a su capacidad para aprender de forma autónoma y su alta precisión en la identificación de patrones complejos en los datos, el Deep Learning se ha convertido en una técnica clave al origen de los últimos avances de la IA.

Cómo funciona el Deep Learning
Las redes neuronales utilizadas en el Deep Learning intentan emular el comportamiento del cerebro humano, permitiendo a los sistemas «aprender» a partir de grandes cantidades de datos. Se componen de múltiples capas de neuronas interconectadas, cada una de las cuales procesa una parte de los datos. Las características extraídas se utilizan en las capas posteriores para extraer características más complejas. Este proceso se repite en cada capa hasta que se extraen las características más abstractas del conjunto de datos.
El término «profundo» en Deep Learning se refiere al uso de múltiples capas en la red. Aunque una red neuronal con una sola capa ya puede realizar predicciones aproximadas, las capas ocultas adicionales ayudan a optimizar y refinar la precisión.
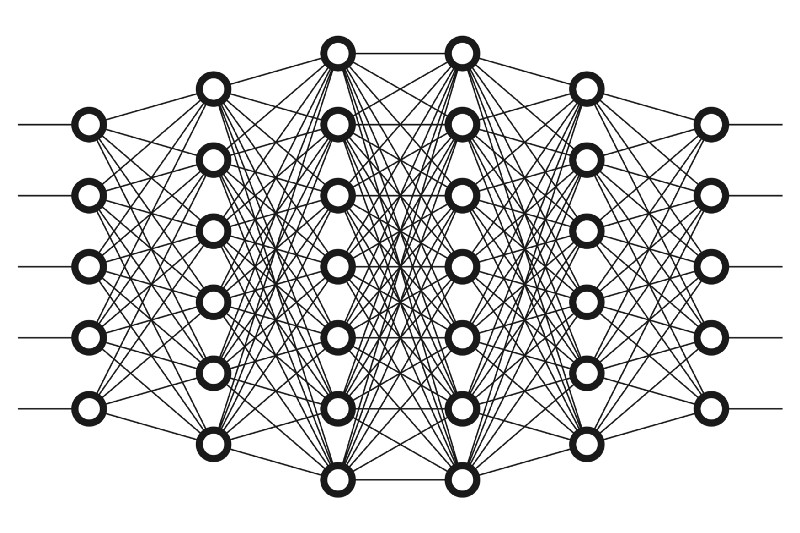
Durante la fase de entrenamiento, el aprendizaje se logra mediante un proceso llamado «propagación hacia atrás» (back propagation), donde el modelo ajusta sus parámetros internos —los pesos y sesgos de las neuronas— para minimizar el error en sus predicciones. Cada neurona en la red tiene un peso que influye en la fuerza de la señal que pasa a través de ella y un sesgo que permite ajustar la salida.
El modelo hace una predicción, y luego se compara esta predicción con la respuesta correcta para calcular el error. Este error se utiliza para realizar ajustes en los pesos de las neuronas, de manera que en la próxima iteración la predicción sea más precisa. Los ajustes se calculan utilizando un algoritmo de optimización, como el descenso del gradiente, que modifica los pesos en la dirección que reduce el error.
Este proceso se repite con muchos ejemplos de entrenamiento y miles, o millones de pases (epoch) en la red, consiguiendo ajustar así progresivamente las características y patrones que son relevantes para la tarea en cuestión.
Con el tiempo y tras numerosas iteraciones, la red neuronal «aprende» a realizar la tarea con una precisión cada vez mayor, ajustando sus parámetros internos para responder de manera efectiva a datos que nunca ha visto antes. Este proceso es lo que hace que el Deep Learning sea particularmente poderoso para tareas que involucran grandes volúmenes de datos y para las que la programación de reglas explícitas sería impracticable o imposible.