Predicción de defectos: ¿de qué estamos hablando?
Imaginemos una fábrica en la que las máquinas funcionan a la perfección con una eficiencia óptima y no generan ningún tipo de defecto en los productos fabricados. Esto sería un escenario ideal, pero la realidad es que esto no ocurre, debido a que las máquinas fallan, se producen desajustes en distintos parámetros que afectan al proceso de producción, y la calidad de algunas piezas se ve afectada.
Hoy en día, según la ASQ (American Society for Quality), los costes relacionados con controles de calidad dentro de las industrias suponen entre un 15% y un 40% de los ingresos.
Esto se debe a que estos procesos se basan principalmente en la detección de defectos a posteriori, es decir, una vez se ha producido la pieza. Es entonces cuando esta se revisa y, o bien se desecha, o bien se corrige ese defecto producido, con todos los costes derivados que esto conlleva tanto económicamente como en tiempo de producción.
En este contexto, la detección preventiva llevada a cabo con técnicas de Inteligencia Artificial (IA), puede ser una gran solución. En este artículo, explicaremos las diferentes alternativas que existen a la hora de ofrecer una solución de IA, relacionadas con analítica predictiva, para la predicción de defectos de calidad, y daremos algunos consejos para poder abordar este tipo de retos.
Pero ¿qué es la analítica predictiva? La analítica predictiva se define como la aplicación de modelos matemáticos para identificar la probabilidad de eventos futuros basados en datos históricos. El principal objetivo es comprender qué ha sucedido para proveer la mejor evaluación de lo que sucederá en el futuro.
Para nuestro caso, queremos predecir si una pieza va a presentar algún tipo de defecto o no a partir de distintos parámetros de fabricación. Existen diferentes técnicas para ello, como los modelos de clasificación o las redes neuronales, que son útiles a la hora de proporcionar estas predicciones.
En este artículo vamos a centrarnos en dos de las técnicas más populares para abordar este tipo de desafíos: Machine Learning supervisado con modelos de clasificación y Deep Learning con redes neuronales.
Predicción de defectos con modelos de clasificación
Los modelos de clasificación son algoritmos diseñados para predecir la clase a la que pertenece un conjunto de datos, basándose en características conocidas como variables predictoras. Estas clases pueden ser binarias (p. ej. hay defecto o no hay defecto) o múltiples (p. ej. diferentes tipos de defectos). Para poder conseguir esta predicción sobre nuevos datos, los modelos de clasificación utilizan datos históricos para aprender patrones, y luego aplicar ese conocimiento sobre los nuevos datos.
La popularidad de estos algoritmos reside, principalmente, en su eficiencia en el procesamiento de datos, lo que supone una alta capacidad en el manejo grandes volúmenes de datos, y su capacidad para adaptarse a diferentes situaciones. Además, estos modelos son relativamente fáciles de entender e interpretar, lo que nos permite identificar las características o variables que más influyen en la predicción de una manera sencilla.
Los algoritmos más utilizados son Random Forest y XGBoost, ambos basados en conjuntos de árboles de decisión. Para hacernos una idea, estos árboles de decisión son como un flujo de decisiones donde cada pregunta reduce las opciones, hasta llegar a una conclusión, igual que en el juego del “¿Quién es quién?”.
Veamos brevemente en qué consisten estos algoritmos, sus ventajas y sus limitaciones.
Random Forest:
En este modelo, cada árbol se construye de manera independiente utilizando una muestra aleatoria de los datos y solo una parte de las características. Luego, las predicciones de cada árbol se combinan para determinar la clase final.
PROS – Este tipo de entrenamiento puede paralelizarse, lo que lo hace más eficiente cuando tratamos grandes conjuntos de datos.
CONTRAS – No funciona bien cuando tenemos datos desbalanceados, a no ser que apliquemos previamente técnicas de balanceo.
XGBoost (Extreme Gradient Boosting):
XGBoost en lugar de construir árboles de forma independiente, mejora iterativamente un modelo existente para minimizar el error de predicción. Cada árbol se construye secuencialmente, y los árboles posteriores se centran en corregir los errores cometidos por los árboles anteriores usando técnicas de aumento de gradiente.
PROS – Una característica importante de XGBoost es que permite una mayor capacidad de ajuste de hiperparámetros, lo que puede llevar a un rendimiento mejor. Asimismo, es capaz de manejar valores ausentes sin necesidad de imputación.
CONTRAS – XGBoost es menos robusto con datos ruidosos. Además, esa cantidad de hiperparámetros supone una mayor complejidad en la configuración.
La diferencia en la construcción y combinación de los árboles de decisión entre ambos modelos hace que, tanto su sensibilidad al sobreajuste, como la complejidad de ajuste de hiperparámetros sea muy diferente. La elección entre uno u otro depende, principalmente, del conjunto de datos específico del problema en cuestión.
En la siguiente gráfica se pueden apreciar de forma visual ambas construcciones:
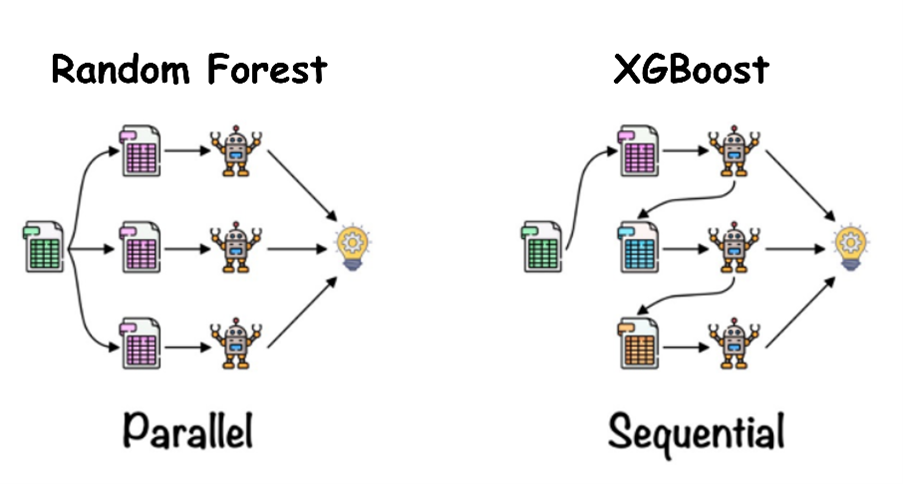
Créditos: https://www.analyticsvidhya.com/blog/2021/06/understanding-random-forest/
Tanto Random Forest como XGBoost son modelos más “tradicionales” en lo que a problemas de clasificación se refiere. Como principal novedad dentro de la IA tenemos las redes neuronales.
Predicción de defectos con redes neuronales
Estos modelos computacionales procesan los datos de una manera inspirada en la forma en que lo hace el cerebro humano. Para ello, utilizan nodos interconectados en una estructura de capas, creando un sistema adaptable que aprende de sus errores y mejora continuamente.
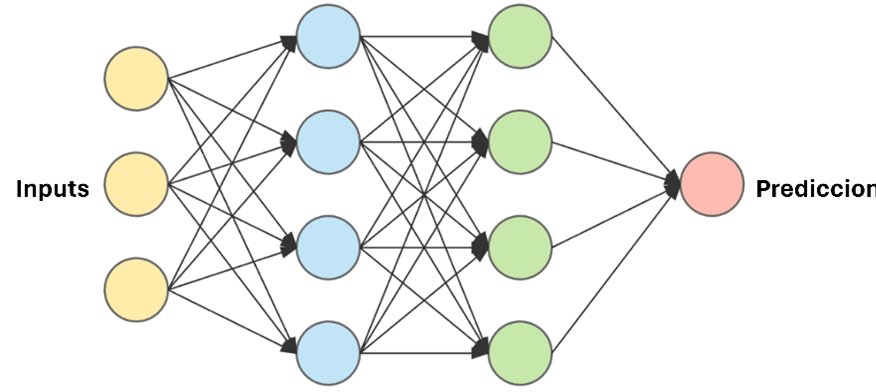
Créditos: https://openwebinars.net/blog/que-son-las-redes-neuronales-y-sus-aplicaciones/
Para la predicción de defectos de calidad, tenemos distintos tipos de arquitecturas de redes neuronales.
La más simple es el perceptrón, formada por una única neurona que es capaz de clasificar de forma binaria. A partir de ella se pueden construir redes con más capas compuestas por estos perceptrones, lo que hace que aumente la complejidad del algoritmo.
También existen redes mucho más complejas como las CNN (Convolutional Neural Networks). Este tipo de arquitectura se utiliza cuando el problema requiere identificar los defectos a partir de imágenes de la pieza.
PROS – Estos algoritmos tienen una alta capacidad de aprendizaje y son muy flexibles, puesto que permiten ser diseñados de mil formas.
CONTRAS – Son modelos que necesitan gran cantidad de datos para poder entrenar, utilizan un alto número de hiperparámetros y tienen un gasto computacional muy elevado. Esto hace que, aunque son métodos muy novedosos, usarlos en algunos problemas de clasificación sencillos sería, como dice la expresión, “matar moscas a cañonazos”.
Entonces: ¿cómo elegir?
Entonces, sabiendo cómo funcionan estos algoritmos ¿Cómo sabemos cuál elegir? ¿Cuál es más recomendable para nuestro caso?
En diferentes proyectos que hemos tenido en PredictLand AI, relacionados con la predicción de defectos en calidad en empresas de automoción, hemos optado por usar modelos de clasificación clásicos como Random Forest y XGBoost. Dieron excelentes resultados para este problema concreto y son sencillos de interpretar por el cliente.
Principal reto: los datos
Recordemos que esos modelos de clasificación se encargan de buscar patrones entre los datos. Por ello, es importante no solo disponer de un buen histórico de datos, sino también que estos sean de calidad.
Pero ¿cómo podemos determinar esa calidad de los datos? Aquí es cuando entra en juego la analítica descriptiva y la comunicación con el cliente. Esta comunicación es clave para comprender los objetivos de negocio y poder así entender los datos para, posteriormente, limpiarlos y construir la información útil para nuestro modelo.
Cuando hablamos de predicción de defectos de calidad dentro de un proceso de fabricación, una de las cosas con las que uno se suele encontrar es con distintas tablas que hacen referencia a diferentes máquinas del proceso. Para poder cruzar todas esas tablas y conseguir una única que recoja todos los datos, es importante que durante todo el proceso la pieza sobre la que se ha de determinar el defecto esté bien identificada.
Hay que tener en cuenta también que las distintas máquinas del proceso pueden tener una gran cantidad de parámetros que pueden actuar como variables predictoras de nuestro modelo. Este análisis de datos nos puede ayudar a tener una primera aproximación de qué variables pueden ser importantes, así como qué forma tienen y las posibles transformaciones que se necesitan para aplicar un modelo u otro.
5 etapas en un caso real
La pregunta que debemos hacernos ahora es, ¿puedo utilizar este tipo de técnicas para mi caso?
Para responderla, vamos a ver los puntos clave para abordar un proyecto de predicción de defectos de calidad basados en nuestra experiencia:
- Reúne la mayor cantidad de datos posibles. Esto ayuda a tener un buen histórico de los diferentes parámetros que hay en la máquina del proceso de fabricación en cuestión.
- Añade datos externos, si es posible, que puedan afectar al proceso de fabricación como la temperatura o humedad del ambiente.
- Analiza los datos para familiarizarte con ellos y poder así determinar qué variables son importantes en el proceso de fabricación. En este punto es útil la comunicación con el cliente para que aporte su conocimiento e intuición acerca del proceso.
- Selecciona varios modelos y ponlos a prueba midiendo diferentes métricas.
- Escoge el modelo que mejor se adapta al problema y el que mejor resultados proporciona y decide, junto con el cliente, la cantidad de piezas sobre la que se quiere dar una alarma de defecto.
Siguiendo estos consejos, se puede lograr un ahorro significativo en costes y tiempo en el proceso de fabricación, mejorando así la eficiencia operativa. Por ejemplo, una empresa que produce 1000 piezas diarias y tiene que revisar 400 de estas piezas, puede beneficiarse utilizando un modelo que detecte el 80% de los defectos dentro del 20% de las piezas fabricadas (lo que serían 200 piezas). Se optimiza así el tiempo del personal encargado de la revisión de calidad.
Conclusión
En resumen, los altos costes asociados a los controles de calidad en las industrias son atribuidos en gran medida a procesos de detección de defectos a posteriori. La introducción de técnicas de IA como Machine Learning supervisado con modelos de clasificación, puede ayudarnos a solventar la detección temprana de defectos de calidad en nuestro proceso de producción.
Sin embargo, el éxito de estos modelos depende en gran medida de la calidad y la disponibilidad de los datos. Por ello, es esencial realizar un análisis de los datos y colaborar con el cliente para comprender los objetivos del negocio y seleccionar las variables relevantes para el proceso de fabricación.
Por último, siguiendo los consejos mencionados, podemos ser capaces de implementar con éxito soluciones de IA en la predicción de estos defectos de calidad. Así conseguimos ahorros significativos tanto en costes como en tiempo.


